Overview of ImageNet Sketch Dataset Classification Using Computer Vision Models
1. Background
Tasks such as recognition and classification are being solved in the field of computer vision for various types of image data. Sketch data, unlike photographs, are abstract and simplified data based on a conceptual understanding of objects. Due to the nature of sketch data, other characteristics commonly found in images, such as color and texture, are often lacking, with a primary focus on the shape and structure of the object.
The purpose of this project is to understand the characteristics of these sketch data and to classify them into appropriate classes by training models to learn the characteristics of objects. Artificial intelligence models using sketch data can be applied to various fields such as digital art, game development, and educational content creation. However, it is necessary to consider data augmentation by reflecting the characteristics of sketch data, which lack detailed features, unlike ordinary image data.
In this project, we analyzed the sketch dataset and experimented with models that fit its characteristics. In addition, we built a better classification model by interpreting and refining the experimental results.
Image classification has a long history of research in the field of computer vision, and various methodologies have been proposed. Among them, Convolutional Neural Network (CNN) models have shown excellent performance in solving image classification problems. To address challenges that arise from deeper network architectures aimed at achieving better performance, models like ResNet, which include residual connections, Vision Transformer (ViT), which takes image patches as input and performs classification using transformers, and ConvNeXt, which redesigns CNN architectures by incorporating effective elements from ViT, have been studied and applied to problem solving.
2. Exploratory Data Analysis
The dataset used in this project consisted of a total of 25,035 data points corresponding to 500 classes from the ImageNet Sketch dataset, and the training data are evenly distributed, with 29 to 31 samples per class. Of these, 15,021 were used for training, and 10,014 were used for evaluation.
Most of the image data sizes are distributed between 400 and 800 pixels, with many images being close to 800 pixels. Additionally, it was confirmed that many images have an aspect ratio between 0.8 and 1.2, making them nearly square. Therefore, it was determined that no additional preprocessing for the aspect ratio was required.
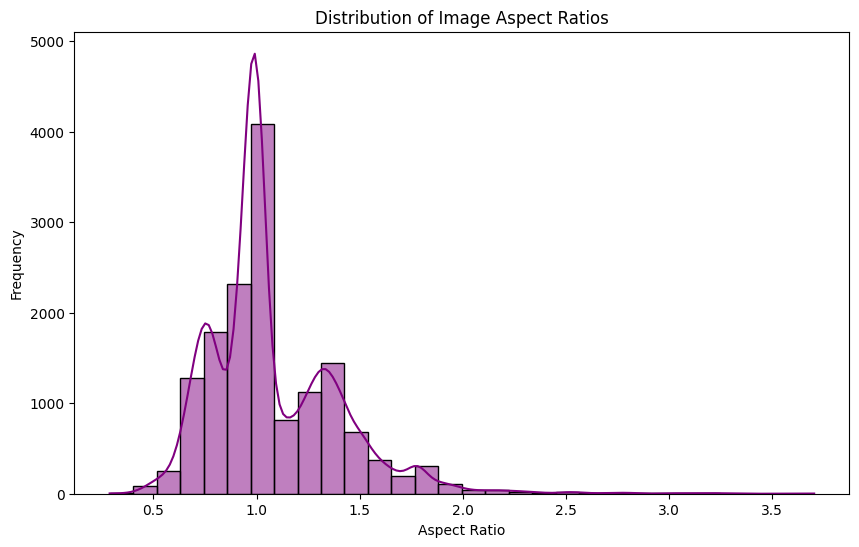 Image Aspect Ratio
Image Aspect Ratio
The average RGB value of the training dataset is distributed between 200 and 250, indicating that the brightness of the image data is generally high. This is presumed to be because, due to the nature of sketch data, most of the background consists of empty or white space, with little to no image content.
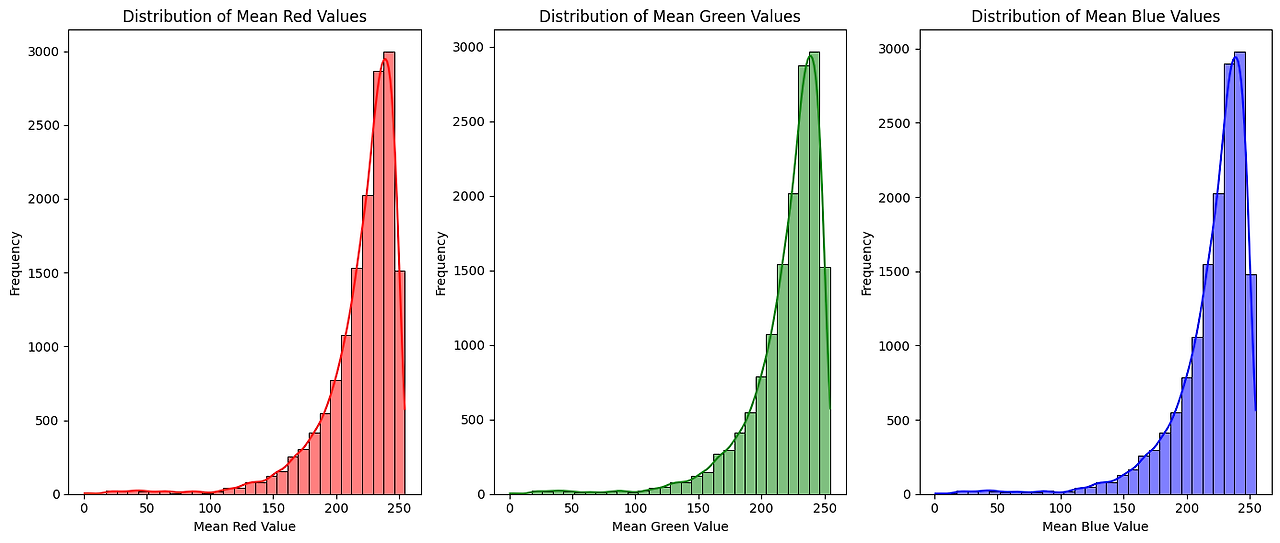 Image Histogram
Image Histogram
3. Data Augmentation
3.1. CutMix
According to Yun et al., the model’s performance was improved by mixing two different images, demonstrating that it is an effective augmentation technique.1 In this project, CutMix was utilized as a data augmentation method to learn various features from multiple images and improve the robustness of the model, as it allows effective training with fewer data than the number of classes.
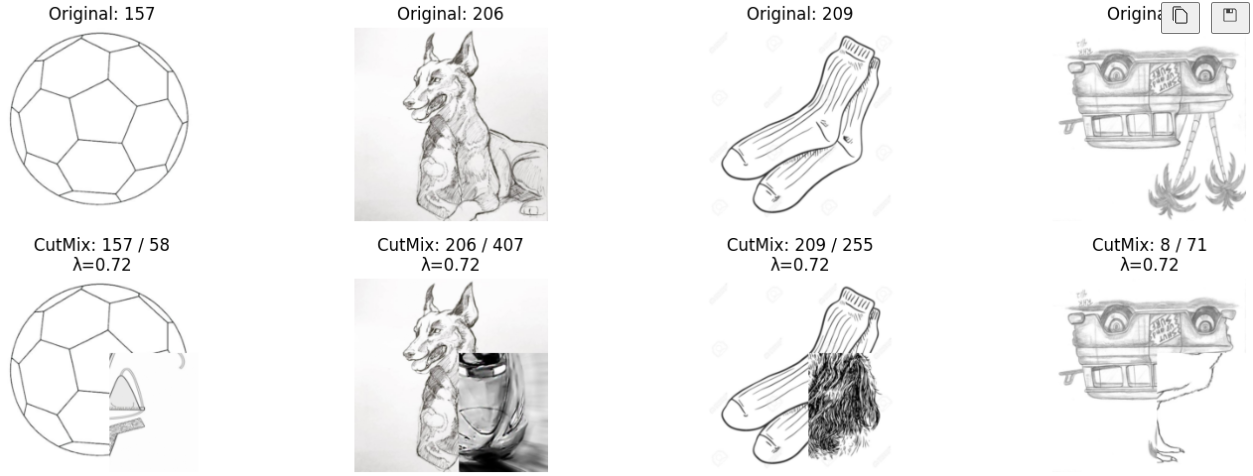 CutMix Example
CutMix Example
3.2. Edge Detection
According to Gerihos et al., CNN models improved accuracy and robustness by configuring datasets to focus only on the shape of objects, addressing the problem of low accuracy when only the shape is preserved.2 In this project, we utilized the Canny Edge detection algorithm to focus on the shape of the sketch dataset.
3.3. Other Augmentations
Sketch data are characterized by important features such as shape, structure, and stroke order. Considering these characteristics, elastic deformation can be applied as an augmentation technique to simulate affine transformations or variability in stroke position and thickness, allowing the model to learn sketch direction and size. We also added Gaussian noise to handle noise or incomplete sketches in the images, and used motion blur to simulate the inaccurate stroke effects common in sketches. Geometric transformations, along with noise and blur augmentations, were grouped under Sketch Albumentations (Sketchab) and applied accordingly.
4. Experiments
4.1. Models
To classify the sketch dataset, we experimented with various models provided by libraries(Torchvision and timm). The main models we experimented with are as follows.
- ResNet : A convolutional neural network based on the deep residual learning framework to address the degradation problem3
- EfficientNet : A convolutional neural network and scaling method that uniformly scales all dimensions of depth, width, resolution using a compound coefficient4
- ConvNeXt : A pure convolutional network model that can compete favorably with state-of-the-art hierarchical vision Transformers across mulitiple computer vision benchmarks, while retaining the simplicity and efficiency of standard CNN5
- DenseNet : A type of convolutional neural network that utilizes dense connections between layers through Dense Blocks6
- MobileNet : A streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks7
- ViT : A model for image classification that employs a Transformer-like architecture over patches of the image8
4.2. Results
First, we compared the accuracy of each model to choose the best one for image classification. The results were obtained by training each model on the training dataset and adjusting the learning rate, starting from an initial rate of 3.00E-04.
ConvNeXt is designed to handle more information and learn more complex representations by stacking more convolutional layers than conventional CNN models, which typically use 3x3 kernels and show strong baseline performance.
| Models | Accuracy |
|---|---|
| ResNet 18 | 0.4329 |
| ResNet 50 | 0.6279 |
| ResNet 101 | 0.5956 |
| DenseNet 121 | 0.4552 |
| Mobile v2 | 0.5760 |
| ViT b 16 | 0.6575 |
| Efficient b1 | 0.7823 |
| ConvNeXt | 0.8224 |
Various pre-processing was performed using ConvNeXt, which showed the best performance based on the baseline, so that the model could learn more about the various features of the object, and the results are shown in the table below. However, due to the limitation of the project execution period, the experiment on the combination of all pre-processing methods could not be conducted.
It was confirmed that the accuracy was improved according to the preprocessing under the same conditions. In particular, it was found that the preprocessing of Sketchab contributes most efficiently to the performance improvement. This can infer that Sketchab is the preprocessing method that most effectively reflects the characteristics of sketch images in the current given dataset.
| Sketch ab | Edge | CutMix | Accuracy |
|---|---|---|---|
| X | X | X | 0.8224 |
| O | X | X | 0.8840 |
| X | O | X | 0.8690 |
| O | O | X | 0.8770 |
| O | X | O | 0.8880 |
5. Conclusion
5.1. Lessons learned
In this project, various models were tested by accessing a remote server via Secure Shell Protocol (SSH), rather than using a local computer environment. Through these experiments, it was confirmed that more state-of-the-art model demonstrated superior performance. Additionally, data augmentation has been shown to provide further performance improvements, emphasizing the need for this process in model training. In particular, augmentations that took into account the characteristics of sketch data proved to be more effective, highlighting the importance of tailored augmentation strategies for specific data types.
5.2. Copyright and Code
This project was a part of a project conducted by Naver AI Tech Boostcamp and was carried out with 6 team members. The dataset used in the project was used under Creative Commons Attribution 4.0 International License. Furthermore, detailed code for the project is available in my github link.
6. References
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo. (2019). CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. ↩︎
Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, Wieland Brendel. (2019). ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. ↩︎
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. (2015). Deep Residual Learning for Image Recognition ↩︎
Mingxing Tan, Quoc V. Le. (2019). EfficientNet : Rethinking Model Scaling for Convolutional Neural Networks. ↩︎
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie. (2022). A ConvNet for the 2020s. ↩︎
Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger. (2016). Densely Connected Convolutional Networks. ↩︎
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam. (2017). MobileNets : Efficient Convolutional Neural Networks for Mobile Vision Applications. ↩︎
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ↩︎