A Journey to Lightweight Audio Language Model | Multi-Modal LLM
1. Introduction
Nowadays, Large Language Model(LLM) is one of the most popular AI topics. LLMs have not only simple text generation ability but also vast knowledge from large-scale data. Due to these characteristics, research on Multi-Modal LLM, using LLM like a human brain and links it with other abilities, is also continuously being conducted.
However, such a versatile LLM requires billions of parameters to gain more capabilities, and it results in increasing the GPU memory required. This requirement makes it difficult to use LLMs on personal devices (such ase edge devices) where large-scale VRAM is not allowed. Therefore, in order for more people to utilize LLM (or Mutli-modal LLM), a lightweight model that does not degrade in performance even with smaller memory is needed.
Therefore, in this project, we aim to achieve balanced modeling that achieves lightweight while maintaining the performance of existing models. To this end, we consider 1) increasing the performance of the model or 2) increasing the efficiency of the model, and 3) finally propose modeling with even performance through self-assessment.
2. Related-Work
2.1. Audio Language Model(ALM)
ALM is a multi-modal model which can perceive audio data and generate text. Compared to LLM which specializes in understanding text, ALM is possible to perform various tasks by combining audio adapters and analyzing the features of the voice itself through pre-training. Generally, ALM includes encoders and LLM to extract features from audio data deliver the features to LLM, mainly using the Mel-spectrogram as shown in the image below.
 Spectrogram Example
Spectrogram Example
There are several ALM tasks : Automatic Audio Captioning(AAC), Automatic Speech Recognition, Question & Answer, Gender Recongintion, etc. To solve these tasks, it is possible to develop individual models for specific task. SLAM is one of the projects which provides various recipies for each task. For example, SLAM-AAC is state-of-the-art ALM for AAC task.1 On the other hand, there is another approach to develop universal model and devise training techniques for multiple tasks like SALMONN2 or QWEN2-Audio3.
Here, we employ SALMONN in order to use it for multiple tasks.
2.2. Large Language Model
In recent years, various models in LLM have emerged and are rapidly developing. For practical purpose, it is appropriate to take open-source LLMs, including Meta’s LLaMA4, Vicuna fine-tuned from LLaMA, Google’s Gemma5, and Chinese startup DeepSeek6.
2.3. Dataset
In this project, we use the following datasets. (Dataset Name : License)
- Librispeech: CC-by-4.07
- MusicNet: CC-by-4.08
- Clotho: CC-by-4.09
- WavCaps: CC-by-4.010
- GigaSpeech: Apache-2.011
- AudioCaps: MIT12
3. Experiment
3.1. Performance Improvement
LLM Backbone Change
First, we try to replace LLM backbone, which is a large part of the model. The existing baseline is based on Vicuna 7B & 13B or LLaMA 3B, and we conduct the experiment with the expectation that the text generation performance and weight reduction would be improved.
The result shows that high performance models are different in terms of task performance and efficiency. Therefore, we decide to adopt LLaMA 3B with the most even distribution of performance and efficiency indices.
| LLM | WER | SPIDEr | Memory(GB) | Inference Time (s) |
|---|---|---|---|---|
| Vicuna 3B | 0.0512 | 0.1803 | 15.7517 | 0.34130 |
| LLaMA 3B | 0.0634 | 0.2027 | 9.1761 | 0.35691 |
| LLaMA 1B | 0.1762 | N/A | 5.4844 | 0.28500 |
| Gemma2 2B | 0.0680 | 0.3707 | 8.0882 | 0.43760 |
| DeepSeek R1 1.5B | 0.0852 | 0.3185 | 6.5197 | 0.41210 |
Encoder Change
In addition, we hypothesize that the model performance can be improved by the change of encoder. Replacing Whisper Encoder with the new version, we confirm this replacement by checking a significant performance improvement.
3.2. Efficiency Improvement
Pruning
Pruning is to identify optimal neuron connectivity without sacrificing performance. We conduct two types of experiments that one is to apply pruned model from huggingface and the other is to apply pruning technique to a model. There are three types of experiments :
- Structured Pruning 20% by weights (pruned20)
- Pruning based on L2-norm (ppl-n10)
- Pruning based on Taylor series (taylor)
There is an improvement of memory, but a diminution of performance. Looking at the result of pruned modles with naked eyes, the models only generate very short sentences or repetitive expressions due to the lack of training. However, we determine not to proceed further training in order to conduct other experiments under our device environment where GPU is limited. In addition, the reason why the increase in Gemma’s inference time could not be identified accurately, but it seems to have overlapped with several processes.
| LLM | Memory(GB) | Inference Time (s) |
|---|---|---|
| LLaMA 3B (base) | 9.1761 | 0.35691 |
| LLaMA 3B (pruned20) | 8.3876 | 0.33480 |
| Gemma2 2B (base) | 8.0882 | 0.43760 |
| Gemma2 2B (ppl-n10) | 7.5012 | 0.48760 |
| Gemma2 2B (taylor) | 7.5012 | 0.54550 |
LoRA Change
Parameter-Efficient Fine-Tuning(PEFT) is used for efficiently adapting large pretrained models to various downstream applications without fine-tuing all parameters. It can be easily applied using config class as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Example
from peft import TaskType, get_peft_model, VBLoRAConfig
...
self.peft_config = VBLoRAConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=lora_rank,
vblora_dropout=lora_dropout,
target_modules
)
self.llm_model = get_peft_model(self.llm_model, self.peft_config)
However, some PEFT are excluded from experiments because they do not operate properly. We find that VB-LoRA can shorten inference time (🔽20.3 %).
Quantization
Quantization is a technique for performing computations and storing tensors at lower bitwidths than floating point precision. It allows for a more compact model representation and the use of high performance vectorized operations on hardware platforms. Here, we implement bitsandbytes for quantizing a model as follows. In addition, flash attention mechanism is appled to decrease computational complexity.13
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16,
)
self.llm_model = AutoModelForCausalLM.from_pretrained(
llm_path,
torch_dtype=torch.bfloat16,
token=token,
quantization_config = config,
use_cache=False
)
The result shows that model quantization reduce memory greatly. Applying additional quantization to LoRA part, we find that inference time is added as the process of data type casting. Thus, we decide to apply it only to the model.
| Quantization | WER | SPIDEr | Memory(GB) | Inference Time (s) |
|---|---|---|---|---|
| N / A | 0.0634 | 0.2027 | 9.1761 | 0.35691 |
| Model Q | 0.0711 | 0.3044 | 5.9618 | 0.38010 |
| Model & LoRA Q(16) | 0.0640 | N/A | 5.5822 | 0.43820 |
| Model & LoRA Q(16) | 0.0660 | N/A | 5.5822 | 0.44160 |
4. Conclusion
4.1. Final Result
Our team conclude a final model that contains new components and quantized model.
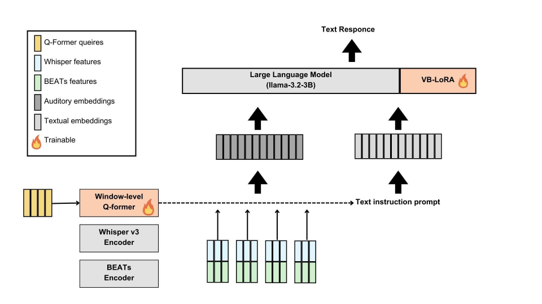
Our Final Model
The below table shows improved performance and efficiency.
| Model (ENV) | WER | SPIDEr | Memory(GB) | Inference Time (s) |
|---|---|---|---|---|
| Baseline (Ours) | 0.0634 | 0.2027 | 9.1761 | 0.35691 |
| Our Model (Ours) | 0.0585 (-7.7%) | 0.3044 (+50.2%) | 5.9618 (-35.0%) | 0.38010 (+15.4%) |
| Our Model (Eval) | 0.0612 (-3.5%) | 0.3218 (+58.8%) | 5.9661 (-35.0%) | 0.23970 (-32.8%) |
- Ours environment : Intel Xeon Gold 6154, NVIDIA V100 (NAVER CLOUD PLATFROM)
- Eval environment : Intel Xeon Platinum 8468, NVIDIA H100
4.2. Further Application
To execute a model with faster runtime, we also try converting pth file to ONNX. However, in the case of SALMONN, the model structure is complicated and it is not possible to convert directly to torch.onnx.export. Thus, I create a wrapper for each part and performed a separate onnx transformation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# Wrapper Example
from models.modeling_whisper import WhisperModel
class WhisperEncoderWrapper(nn.Module):
def __init__(self, whisper_path):
super().__init__()
self.encoder = WhisperModel.from_pretrained(whisper_path).encoder
for name, param in self.encoder.named_parameters():
param.requires_grad = False
self.encoder.eval()
def forward(self, spectrogram):
embeds = self.encoder(spectrogram, return_dict=True).last_hidden_state
return embeds
def main():
args = parse_args()
cfg = Config(args)
model_config = cfg.config.model
data_config = cfg.config.datasets
whisper = WhisperEncoderWrapper(model_config.whisper_path)
beats = BEATsEncoderWrapper(model_config.beats_path)
samples = {
"spectrogram" : torch.randn(1, 128, 3000),
"raw_wav" : torch.rand(1, 220320, dtype=torch.float32), # onnx cannot track ndarray
"padding_mask" : torch.randint(0, 2, (1, 220320), dtype=torch.bool),
"text" : "And like staring down the barrel of this coming school year.",
"task" : "asr",
"Q" : None,
"id" : "GigaSpeech/16/POD0000010316_S0000117.wav"
}
# convert whisper encoder
torch.onnx.export(
whisper,
samples["spectrogram"],
"/data/ephemeral/home/syp/onnx/whisper/whisper.onnx",
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input' : {0 : 'batch_size'},
'output' : {0 : 'batch_size'}
},
export_params=True,
do_constant_folding=True
)
Via the code, the model can be exported to onnx format as below. The image is captured on Netron.
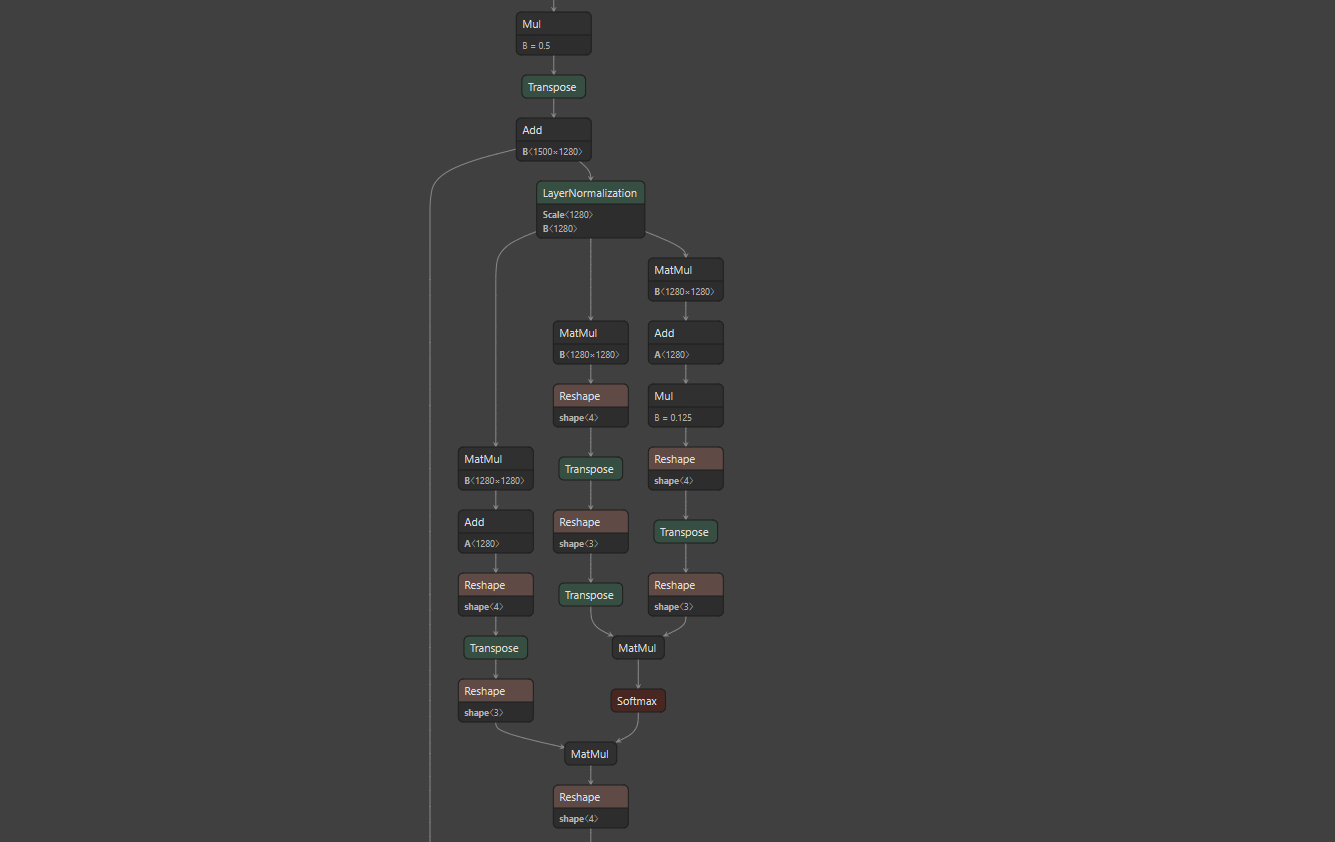
ONNX transformation
4.3. Copyright and Code
This project is a corporate hackathon project with Nota AI held at boostcamp AI Tech, managed by NAVER Connect Foundation, and it was carried out with 5 team members. It is available to check source code in GitHub Repository link.
5. References
Wenxi Chen, Ziyang Ma, Xiquan Li, Xuenan Xu, Yuzhe Liang, Zhisheng Zheng, Kai Yu, Xie Chen. (2024). SLAM-AAC: Enhancing Audio Captioning with Paraphrasing Augmentation and CLAP-Refine through LLMs. ↩︎
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang. (2023). SALMONN: TOWARDS GENERIC HEARING ABILITIES FOR LARGE LANGUAGE MODELS. ↩︎
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou. (2024). Qwen2-Audio Technical Report. ↩︎
Llama Team, AI @ Meta. (2024). The Llama 3 Herd of Models. ↩︎
Gemma Team, Google DeepMind. (2024). Gemma 2: Improving Open Language Models at a Practical Size. ↩︎
DeepSeek AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. ↩︎
Vassil Panayotov, Guoguo Chen, Daniel Povey and Sanjeev Khudanpur. ICASSP 2015 (pdf). LibriSpeech: an ASR corpus based on public domain audio books ↩︎
Reddy, Chandan KA, Vishak Gopa, Harishchandra Dubey, Sergiy Matusevych, Ross Cutler, and Robert Aichner. (2021). MusicNet: Compact Convolutional Neural Network for Real-time Background Music Detection ↩︎
“Clotho: An Audio Captioning Dataset”, Konstantinos Drossos, Samuel Lipping, Tuomas Virtanen, ICASSP 2020 (pdf) ↩︎
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D. Plumbley, Yuexian Zou, Wenwu Wang. (IEEE 2024).WavCaps: A ChatGPT-Assisted Weakly-Labelled Audio Captioning Dataset for Audio-Language Multimodal Research (pdf) ↩︎
Guoguo Chen, Shuzhou Chai, Guanbo Wang, Jiayu Du, Wei-Qiang Zhang, Chao Weng, Dan Su, Daniel Povey, Jan Trmal, Junbo Zhang, Mingjie Jin, Sanjeev Khudanpur, Shinji Watanabe, Shuaijiang Zhao, Wei Zou, Xiangang Li, Xuchen Yao, Yongqing Wang, Yujun Wang, Zhao You, Zhiyong Yan. (2021). GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio ↩︎
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, Gunhee Kim. (NAACL 2019). AudioCaps: Generating Captions for Audios in The Wild ↩︎
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. ↩︎